
Reducing Unscheduled Downtime: Fighting for Each Additional ‘Nine’ of Network Availability
Reconciling network management strategies with business needs involves balancing uptime service level requirements, security risk, and cost. The ROI of applying advanced out-of-band solutions and network management automation can rapidly exceed the costs of maintaining more “business as usual” processes by making higher uptime and service levels possible, while also reducing security risk.
Are Your Network Availability Expectations in Line with Your Business Requirements?
Achieving uptime in a corporate network that even approaches Three Nines is a daunting task requiring less than 8.8 hours of unscheduled downtime over the span of a year across all of the devices that create the network. Rapid recovery from any issue requires network management automation and assistance for network admins to even come close to meeting high availability requirements. Finally, budgets and business requirements for network availability and risk tolerance play into decisions on how networks are designed and managed.
In-Band versus Out-of-Band
Network infrastructure management can be in-band or over various types of out-of-band interactions. Most basic is accessing a network device to change configuration through the production network. That’s in-band. Using SNMP queries from centralized network management software to that device over the network it’s on is also in-band. Connecting a laptop to a device’s console port is considered an out-of-band connection since it’s not over the network.
In most environments, these methods hit challenges relatively quickly that either create more work for already-busy network admins or can result in an unexpected downtime lasting longer than even a three-nine metric allows for several reasons:
- Riding the crash cart | Directly connecting to a managed device over the console port means being onsite, and due to limitations on cable length for serial console connections, typically right there in the network closet or data center rack. This means trained 24/7 onsite staff or factoring in travel time to get highly trained staff onsite.
- Managing the network over the network | Connecting over the production network adds traffic to the network and workload to the infrastructure devices themselves. This is the reason that SNMP queries from centralized network management software are often limited to once every 5 minutes, or even longer intervals. It’s also considered less secure that managing over an out-of-band link because devices must be configured to accept connections from other devices and software.
Centralizing Access to Devices
Next, setting up access to infrastructure devices over a secondary network connection, perhaps through a dedicated management switch on another network does remove some risk. The production network no longer must bear the additional management traffic, and admins can access device management GUIs or CLIs, including server baseboard management.
For many network infrastructure devices like routers, switches, firewalls, and more, accessing them via a network connection requires the device to be operating in a highly functional state to reach them through Layer 4 on the OSI Model. This is the reason for console ports that allow communication with the device at a lower level of functionality on Layer 2 or 3 for basic commands and troubleshooting. Even if the device isn’t able to connect to an IP network, the console port is generally available.
Console Access Increases Reliability, Secondary Networks Increase Resilience
Adding a console server gives access to devices at this level, often providing connections to multiple devices even when there is not a functioning network. Connecting a console server with a secondary communication link like a cellular or POTS modem increases resiliency by allowing for remote access even when the primary network is down. For really remote networks, this could even be a satellite link. If you are counting the minutes during an outage, this can be a big step toward more rapidly solving a problem by connecting remote admins to the gear as if they were there with a crash cart. In addition to providing connectivity, console server management software can integrate with access security platforms to ensure granular access where only trusted people can reach the gear they have rights to work on.
Speeding Up Time to Recovery
Secure remote access can have a big impact on getting people working toward solving issues by removing travel time. The next challenge of progressing toward higher availability is that sometimes it takes a while for a problem to be noticed or officially reported. If centralized network management tools are only poling every 5-minutes, a problem might not trigger an initial alert until after the Five Nines metric has been broken (~5 minutes annually!), and already over a quarter of the time for maintaining Four Nines has passed. Faster monitoring and alerting are required.
Availability | Downtime Per Year |
90% (One Nine) | 36.53 days |
99 (Two Nines) | 3.65 days |
99.9% (Three Nines) | 8.77 hours |
99.99% (Four Nines) | 52.6 minutes |
99.999% (Five Nines) | 5.26 minutes |
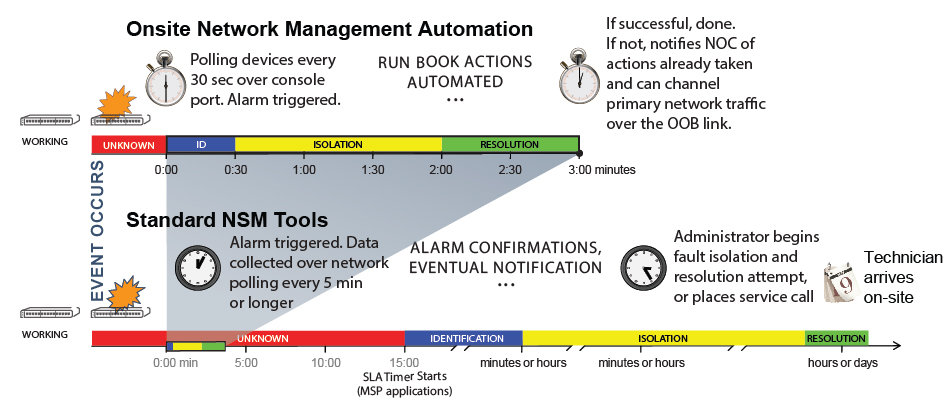
It needs to poll at a higher frequency than SNMP, and still be over the console port to keep from bogging down the device. Monitoring needs to move to the edge, in the rack with managed devices. For high availability, a comprehensive view of all network infrastructure is needed. Each device that’s in the critical path for creating the network should be monitored continuously. Why? Because when there is a network issue, recovery goes through four standard phases:
- Unknown | The downtime clock has started ticking, but the problem hasn’t been discovered yet.
- Identification | Monitoring detects the problem and alerts, hopefully through IT methods before user complaints or disruptions to operations.
- Isolation | This is the stage of many questions: Who’s problem is this anyway? Is it an issue with the provider or within IT’s network? Which device in the rack is causing the problem?
- Resolution | Only when it’s known who owns the problem and the root cause is determined can the problem be resolved.

A Platform for Network Management Automation
This is where automation must come in to even consider hitting the Four Nines range of availability. Unlike network management software polling from the NOC, reliable management automation must come from a point of access resilience, like a console server directly connected to managed devices over their console port with a secondary network connection. This is the ideal platform for driving network management automation, by deploying network management software, processing power, and secure onboard storage for configuration and OS files. Here are some of the benefits of this platform:
- Frequent, intensive monitoring | Since the managed devices’ networking functions are not taxed, nearly continuous polling can alert of issues within seconds.
- Sophisticated rules engine | Receiving the feed from the monitoring is local processing of the data to determine if a device is behaving normally or not. This state-awareness feeds decision trees that directly correspond to the network group’s run book can gather more data, look for trends, and trigger automated actions to start the resolution phase in moments reducing downtime by eliminating the delays of a human response.
- An onsite assistant for bigger issues | When an issue exceeds automated responses, like a device that needs replacement, the platform can reduce the challenges on the IT team with functionality like onboard FIPS 140-2 encrypted storage of config and OS files. Just cable up the replacement device and it’s recognized and automatically configured.
A Happy Network is a More Secure Network
Downtime is traditionally the devil’s playground in networking. When the network is down SNMP polling is useless, logging of device access isn’t recorded, and desperate admins trying to get things working again resort to break-glass passwords and ad-hoc procedures.
With a console-based platform for network automation, all interactions with network infrastructure goes through access security, gets logged for both user input and device response, which is handy for post-mortem evaluations, as well as automatically backing-out errant changes.
Related Posts

July 23, 2024 Industry Trends
When there’s no time to be thunderstruck… are you ready for the next Crowdstrike outage?
Every time there is a major news event about a global IT outage like this weekend’s Crowdstrike event, my wi.....

December 11, 2023 Technical Articles
Reducing Unscheduled Downtime: Fighting for Each Additional ‘Nine’ of Network Availability
Reconciling network management strategies with business needs involves balancing uptime service level requirem.....